Render archives as HTML, PDF, and image files Leave feedback
On this page
GroupDocs.Viewer for Java allows to view the list of content of archive files and represent it in HTML, PDF, PNG and JPEG formats. It also allows to extract any arbitrary file from the archive. It does not require to use any third-party file archiver and/or compression software to display archive file contents within a Java application (web or desktop).
Displaying a list of content of archive files in GroupDocs.Viewer is similar to other formats. You need to create an instance of the Viewer class, and specify an archive document in its constructor as a path to the file or a byte stream. Optionally, you can pass a load options, where a password for opening an encoded archive document can be specified. Then you need to select a desired output format, in which the archive content will be represented: HTML (HtmlViewOptions), PDF (PdfViewOptions), PNG (PngViewOptions), or JPEG (JpgViewOptions). Finally, call the Viewer.view() instance method to obtain a result.
GroupDocs.Viewer for Java had support of archive formats from its very beginning. However, starting from the version 25.6 the archive processing module was completely reworked. In short, the way of displaying a list of entries from the archive was completely changed, as well as a final representation. Also, the performance was drastically improved. The public options are left the same, the only change in a public API is an setItemsPerPage() property of ArchiveOptions class, which now is marked as obsolete because it has no effect now. This article explains and displays the new archive processing module. If you’re using the older versions of the GroupDocs.Viewer before the 25.6, the old version of this article can be found here.
GroupDocs.Viewer supports the following archive file formats:
- .7Z (7-Zip Compressed File)
- .BZ2 (Bzip2 Compressed File)
- .GZ (Gnu Zipped Archive)
- .RAR (WinRAR Compressed Archive)
- .TAR (Consolidated Unix File Archive)
- .TGZ / .TAR.GZ (Gzipped Tar File)
- .TXZ / .TAR.XZ (XZ Compressed Tar Archive)
- .XZ (XZ Compressed Archive)
- .ZIP (Zipped File)
- .ZST / .TAR.ZST / .TZST (Zstandard)
- .ISO (Optical Disk Image ISO-9660)
- .CAB (Cabinet)
- .WIM (Windows Imaging Format file)
GroupDocs.Viewer can detect the archive file format automatically based on information in the file header.
The 1st stage of document processing using the GroupDocs.Viewer is loading the document, and archives are not the exceptions. The simplest way is just to path the absolute or relative path of the archive file to the constructor of the Viewer class. If an archive document is represented as a InputStream, this stream can be specified in the overload of the constructor of the Viewer class as well, but make sure that this stream is readable (available()) and its position points to the correct place. Finally, if an archive is encoded and password-protected, and you know this password, it should be specified in the LoadOptions, or a GroupDocsViewerException exception will be thrown instead.
Code sample below shows loading of two archive files into two Viewer instances: 1st file is specified by path, while 2nd — by a stream and with load options with password.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.LoadOptions;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
public class LoadingArchive {
public static void view() throws FileNotFoundException {
String inputArchivePath = "Archive.zip";
try (Viewer viewer1 = new Viewer(inputArchivePath))
{
// view it
}
InputStream inputArchiveStream = new FileInputStream(inputArchivePath);
LoadOptions loadOptions = new LoadOptions();
loadOptions.setPassword("password");
try (Viewer viewer2 = new Viewer(inputArchiveStream, loadOptions))
{
// view it
}
}
}
Archive.zip is sample archive used in this example. Click here to download it.
After the archive document is loaded and an instance of the Viewer class is created, it can be viewed using a Viewer.view() instance method. The “viewing” means displaying a list of content, stored within an archive, in desired output format. In general, this is a tree view, with folders and files, stored within these folders, sorted by default Windows-based order. This means that within one folder all subfolders are located first, sorted in lexicographic order, followed by files, also sorted in lexicographic order. However, the GroupDocs.Viewer implements not a “pure” lexicographic order, but a Windows-like “natural” order, where “file10.txt” is located after the “file9.txt”, but not before it.
Like for all supported formats, GroupDocs.Viewer supports 4 output formats for the representation: HTML, PDF, PNG, and JPEG.
For saving the documents (including archives) to the HTML format the GroupDocs.Viewer provides a HtmlViewOptions class. Currently, there is only one way to create an instance of this class: by using the forEmbeddedResources() static method. When using this (forEmbeddedResources() method, all the resources (stylesheets, raster and vector images, and fonts) are stored inside the HTML markup in base64 encoding.
In the context of archive documents and their rendering to HTML format, the resultant HTML document, which contains a list of files and folders within the archive, contains only stylesheet and icons, representing the folder or format of the particular file, as SVG vector graphics. When saved with embedded resources, the stylesheet is placed in the STYLE element in the HTML -> HEAD section, while SVG images are located inside this stylesheet in base64 encoding. When saved with external resources, the stylesheet is also placed in the STYLE element in the HTML -> HEAD section, but it contains the references to the SVG images that are stored separately. Need to mention that the HTML document contains only those SVG icons, which are necessary for displaying the formats of only those files, which are present in the archive. For example, if a particular archive does not contain the PDF file(s), there will be no SVG icon, which represents the PDF format, in the HTML resources.
GroupDocs.Viewer by default produces paged HTML results — input documents are splitted on pages, and each page is represented by a separate HTML document. There is also a HtmlViewOptions.setRenderToSinglePage() boolean property (flag) in the HtmlViewOptions class — when enabled, the GroupDocs.Viewer produces a single HTML document for the whole input document with all its pages. But archives are pageless in their nature — they store files and folders, and have no concept of “pages” like PDF documents, for example. That’s why for any input archive document the GroupDocs.Viewer produces only a single output HTML document, and there is no matter which value has the setRenderToSinglePage() boolean flag.
The code example below demonstrates how to render an input archive file to an HTML document with embedded resources.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.HtmlViewOptions;
public class RenderToHTML {
public static void view() {
HtmlViewOptions htmlEmbeddedOptions = HtmlViewOptions.forEmbeddedResources("Embedded.html");
try (Viewer viewer = new Viewer("SingleRootFolder.zip"))
{
viewer.view(htmlEmbeddedOptions);
}
}
}
SingleRootFolder.zip is sample archive used in this example. Click here to download it.
Embedded.html is rendered HTML document. Click here to download it.
Screenshot below shows how the output HTML document looks like in a web browser for the archive with a huge amount of files and folders and deep nesting level, when the GroupDocs.Viewer works in licensed mode. Take a note that the GroupDocs.Viewer displays a metadata for the files: a size in bytes and modification date. The modification date can be displayed not for all archive formats, but only for those, which support it.
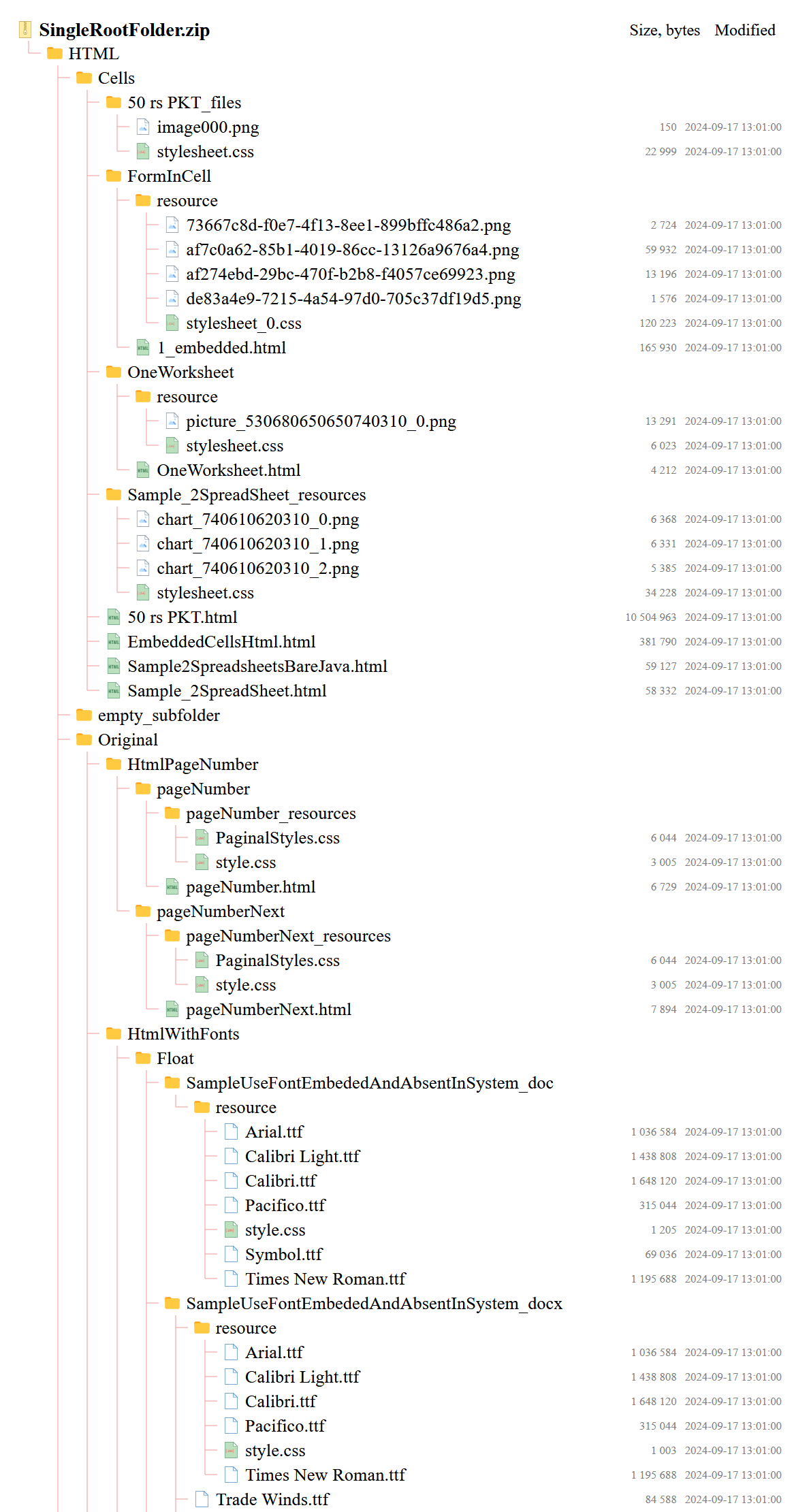
Also please note that for the archive documents the HTML rendering mode is the highest quality among all the others and also has the best performance.
PDF format by its nature has pages, so the list of files and folders from the archive is paginated when rendering to PDF format. Number of pages in this output PDF cannot be specified and it depends only on the number of entries (files and folders) within the input archive.
PdfViewOptions class must be used in order to render archive documents as PDF. All standard PDF-related operations like protecting, watermarking, reordering pages, tuning the images quality and size, can be applied to the output PDF document and are described in the article “Render to PDF” and its sub-articles.
Code example below shows how to display the list of content of a specified archive file in PDF format.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.PdfViewOptions;
public class RenderToPdf {
public static void view() {
PdfViewOptions pdfOptions = new PdfViewOptions("Output.pdf");
try (Viewer viewer = new Viewer("SingleRootFolder.zip"))
{
viewer.view(pdfOptions);
}
}
}
SingleRootFolder.zip is sample archive used in this example. Click here to download it.
Output.pdf is rendered Pdf document. Click here to download it.
Screenshot below shows how the output PDF looks like in a PDF Reader for the archive with a huge amount of files and folders and deep nesting level, when the GroupDocs.Viewer works in licensed mode. Take note how a list of entries is splitted on several pages.

PngViewOptions and JpgViewOptions are responsible for saving archives to the PNG and JPEG raster image formats respectively. Like for the PDF, if the list of archive content cannot fit into the area of one image, it will be paginated and spread across multiple images.
Size of the output images will be calculated automatically based on the specific archive and its content, but it is possible to change the image size using the Width, Height, MaxWidth, and MaxHeight properties of the PngViewOptions and JpgViewOptions classes. An article “Render to PNG or JPEG” describes the tuning and post-processing of PNG and JPEG images in detail.
Because one PNG or JPEG image may contain only the one “page”, for the archives with a significant number of folders and files there will be created several “pages” and thus produced several images. The constructors of the PngViewOptions and JpgViewOptions classes have overload, which allows to specify the template string for the output image files, and the GroupDocs.Viewer fills this template while saving with a sequential page number, which starts from “1”.
Code example below shows rendering of the same input archive file to the two folders with images: one folder with “PNG” name contains page images in PNG format, while another with “JPEG” name — in JPEG format. For both formats the same amount of “page-images” will be generated.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.JpgViewOptions;
import com.groupdocs.viewer.options.PngViewOptions;
public class RenderToPNGJPEG {
public static void view() {
String pngFolderPath = "PNG";
String jpegFolderPath = "JPEG";
PngViewOptions pngOptions = new PngViewOptions(pngFolderPath + "\\page-{0}.png");
JpgViewOptions jpegOptions = new JpgViewOptions(jpegFolderPath + "\\page-{0}.jpeg");
try (Viewer viewer = new Viewer("SingleRootFolder.zip"))
{
viewer.view(pngOptions);
viewer.view(jpegOptions);
}
}
}
SingleRootFolder.zip is sample archive used in this example. Click here to download it.
PNG.zip is an archive that contains rendered .png files. Click here to download it.
JPEG.zip is an archive that contains rendered .jpeg files. Click here to download it.
All 4 option classes — HtmlViewOptions, PdfViewOptions, PngViewOptions, and JpgViewOptions — contain a ArchiveOptions property of the ArchiveOptions type. This class has two properties, which allow users to modify a rendering of the list of archive content and are described below.
By default the GroupDocs.Viewer displays all content inside the archive — all folders, subfolders and files with any nesting level till the end. However, in some cases it is required to display only a part of the list of archive content, for example, only content of some specific folder (including its subfolders), which is located in the given archive.
The setFolder() property of a String type allows to do that. It obtains a folder name or relative path, which is located inside the given archive, and if the archive truly contains such a folder — only its content will be displayed. Otherwise, if no folder with such name or path was found in the archive, the whole archive content will be listed, as usual.
When GroupDocs.Viewer renders a list of archive content, it displays the archive document name at the top of the output document, as a root node for all folders and files inside an archive. When an archive document is specified as a file, its filename will be used as the archive document name. If an archive document is specified as a stream, a standard template name will be used.
With the setFileName() property of the ArchiveOptions type it is possible to specify a displayed archive document name explicitly. Just create an instance of the FileName class, specify desired archive name in its constructor, and assign this instance to the ArchiveOptions.setFileName() property.
Code sample below shows using the setFolder() property and setFileName() property simultaneously for the same loaded archive file. Rendering is performed to the HTML format with embedded resources. It is assumed that a valid license is set.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.FileName;
import com.groupdocs.viewer.options.HtmlViewOptions;
public class RenderToHTMLWithOptions {
public static void view() {
HtmlViewOptions htmlEmbeddedOptions = HtmlViewOptions.forEmbeddedResources("FolderAndFileName.html");
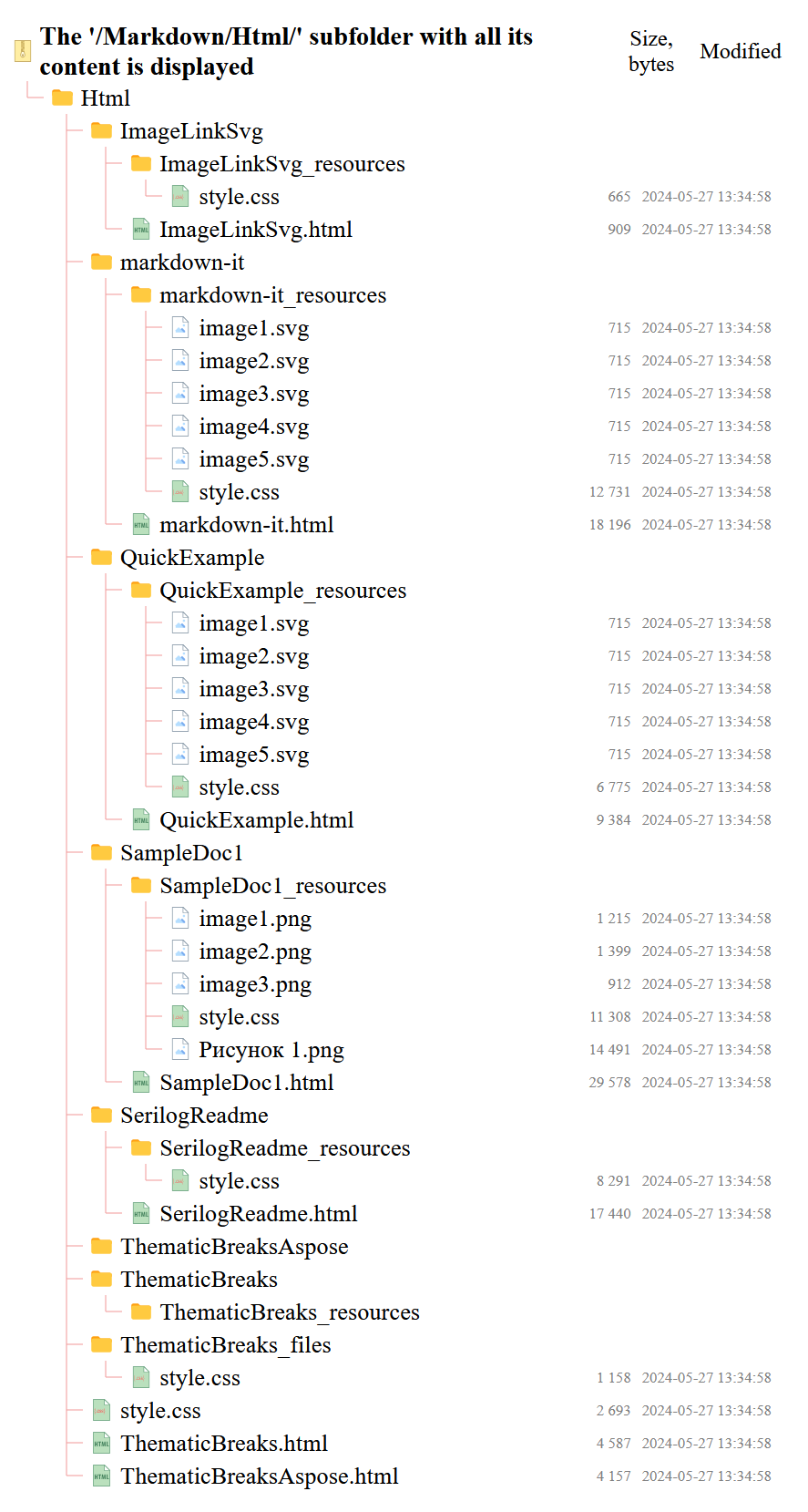
htmlEmbeddedOptions.getArchiveOptions().setFolder("Markdown/Html");
htmlEmbeddedOptions.getArchiveOptions().setFileName(new FileName("The '/Markdown/Html/' subfolder with all its content is displayed"));
try (Viewer viewer = new Viewer("ManyFilesAndFolders.7z"))
{
viewer.view(htmlEmbeddedOptions);
}
}
}
ManyFilesAndFolders.7z is sample archive used in this example. Click here to download it.
FolderAndFileName.html is rendered HTML document. Click here to download it.
Despite code sample above shows using the Folder and FileName properties when displaying the archive content in HTML format, but these properties are working the same when displaying the archive content in all other formats — PDF, PNG, and JPEG.
Screenshot below shows the result of the code sample above.
While displaying a list of files and folders inside the archives is the main purpose of the GroupDocs.Viewer, it also allows to extract files from archives by their paths. In the GroupDocs.Viewer terminology the files inside archives are so-called “attachments”.
In general, the extracting of specific attachment (file) from the given archive document is made in the next steps:
- Create a
Viewerinstance and load an archive document into its constructor. UseLoadOptionsif necessary. - Get a list of all attachments (files), stored inside an archive, by calling a
Viewer.getAttachments()parameterless method or its cancellable overload. - Find and select a particular
Attachmentinstance from the list, which you want to save. - Prepare a destination
OutputStreamwhere you want to write the attachment. Make sure the stream is not null, is writable, and supports seeking if required. - Write the previously selected attachment to a prepared stream using the
Viewer.saveAttachment(Attachment, java.io.OutputStream)method or its cancellable overload. - Alternatively, if you want to extract and save all files from the given archive, just iterate over the list of attachments and call a
Viewer.saveAttachment()method for every attachment in a step.
Take note that extracting files from the archive and viewing its content are different operations, which are not dependent on each other — you may render the list of archive contents without extracting the files, and vice versa.
Also technically step #2 is not necessary — if you know the exact full name (this includes its relative path) of the desired file to extract, there is no need to get a list of all attachments, because the instance of the Attachment class can be created manually and passed directly to the Viewer.saveAttachment() method.
Code example below shows all the described operations with the attachments.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.caching.extra.CacheableFactory;
import com.groupdocs.viewer.results.Attachment;
import java.io.*;
import java.util.List;
public class ExtractingFiles {
public static void view() {
try (ByteArrayOutputStream attachmentStream = new ByteArrayOutputStream();
Viewer viewer = new Viewer("ManyFilesAndFolders.7z"))
{
List<Attachment> allAttachments = viewer.getAttachments();
//Iterate over all attachments and save them
for (Attachment attachment : allAttachments)
{
System.out.println("- "+attachment.getFilePath()+" - "+attachment.getFileType()+" - "+attachment.getSize()+" bytes");
viewer.saveAttachment(attachment, attachmentStream);
}
//Create one Attachment manually and save it
Attachment oneAttachment = CacheableFactory.getInstance().newAttachment("/Images/PNG/Watermark.png", "/Images/PNG/Watermark.png");
try (OutputStream extractedFile = new FileOutputStream("Watermark.png"))
{
viewer.saveAttachment(oneAttachment, extractedFile);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
ManyFilesAndFolders.7z is sample archive used in this example. Click here to download it.
Watermark.png is rendered PNG file. Click here to download it.
Like for all other supported formats, the GroupDocs.Viewer supports getting the view info for the archive documents. This means that for the loaded archive a GroupDocs.Viewer can grab metadata like exact format, whether or not it is password-protected, list of folders inside archive, and a number of pages, which the GroupDcos.Viewer will produce in case when rendering to PDF, PNG, or JPEG will be selected. More info about retrieving the document information in general may be found in the corresponding article.
In order to retrieve metadata about specific archive, the Viewer.getViewInfo() method must be called. This method obtains an instance of ViewInfoOptions class, which can be created from its own or from existing view options. The GroupDocs.Viewer constructs the metadata about the archive in accordance to the passed ViewInfoOptions and its specific settings. For example, for the HTML-based info options the number of returned getPages is always “1” (because the displaying to the HTML format is pageless), while for the PDF, PNG and JPEG there will be some specific page number depending on count of files and folders within the archive.
In the context of archives the Viewer.getViewInfo() method returns an instance of the ArchiveViewInfo class, which is the direct inheritor of the ViewInfo class. Except for the properties present in the ViewInfo, the ArchiveViewInfo provides a getFolders() property of List<String> type — it contains a list of all folders, stored in the archive. Please note that the GroupDocs.Viewer creates a new List with folder names every time when method Viewer.getViewInfo() is called. Also ArchiveViewInfo.getFolders() property does not take into account the value of the ArchiveOptions.getFolder() property, even if ViewInfoOptions was created from such an option — so ArchiveViewInfo.getFolders() always returns a complete list of folders inside the archive.
Concluding: to get the ArchiveViewInfo, just load the archive document to the Viewer constructor, create a relevant ViewInfoOptions, call the Viewer.getViewInfo() and cast the returned ViewInfo instance to the ArchiveViewInfo type.
Code sample below demonstrates all the described information.
import com.groupdocs.viewer.Viewer;
import com.groupdocs.viewer.options.ViewInfoOptions;
import com.groupdocs.viewer.results.ArchiveViewInfo;
import com.groupdocs.viewer.results.FileInfo;
import com.groupdocs.viewer.results.Page;
public class GetArchiveViewInfo {
public static void run() {
ViewInfoOptions viewInfoOptions = ViewInfoOptions.forPdfView();
try (Viewer viewer = new Viewer("E:\\GitHub_Examples\\GroupDocs.Viewer-Docs\\java\\sample-files\\rendering-basics\\render-archives\\MixedContent.7z"))
{
FileInfo fileInfo = viewer.getFileInfo();
System.out.printf("Encrypted: %s%n", fileInfo.isEncrypted() ? "yes" : "no");
ArchiveViewInfo viewInfo = (ArchiveViewInfo)viewer.getViewInfo(viewInfoOptions);
System.out.printf("Archive format: %s%n", viewInfo.getFileType());
System.out.printf("Number of pages when saving to PDF: %s%n", viewInfo.getPages().size());
System.out.println("List of all pages with their metadata, when rendering to PDF:");
for (Page page : viewInfo.getPages())
{
System.out.printf(" - Page #%d - %dx%dpx%n", page.getNumber(), page.getWidth(), page.getHeight());
}
System.out.println("List of folders in the archive document:");
for(String folder : viewInfo.getFolders())
{
System.out.printf(" - %s%n", folder);
}
}
}
}
Encrypted: no
Archive format: 7Zip (.7z)
Number of pages when saving to PDF: 1
List of all pages with their metadata, when rendering to PDF:
- Page #1 - 793x1122px
List of folders in the archive document:
- /CHM/
- /CSS/
- /Images/
- /Images/ICO/
- /Images/JPEG/
MixedContent.7z is sample archive used in this example. Click here to download it.
Despite the new archive processing module being introduced in the GroupDocs.Viewer version 25.6, it is consequentially and constantly improved with new features and enhancements.
First of all, we constantly add support for new archive formats. In the version 25.9 added support for the LHA/LZH, Cabinet (CAB), and Windows Imaging (WIM) archive formats.
Also the version 25.9 has introduced an improvement — now the last modification date is shown also for the entries of CAB, ISO, and TAR archives.
Starting from this version the GroupDocs.Viewer supports listing content of the nested archives — archives inside archives, — and this nesting level is indefinite. This means that one archive file may contain another, inner, and this inner contains other sub-inner archives, and so on… if these sub-archives are not password-protected, then the GroupDocs.Viewer will open them and explore their content. Screenshot below shows such a sample archive, rendered with the GroupDocs.Viewer.

Sample file “all-formats.zip”, shown on a screenshot, actually has no folders “sample.tar” and “sample.zip” — they are actually files, inner archives inside outer archive. But GroupDocs.Viewer has opened and listed their content and thus displayed them as the folders. Need to mention that rendering nested archives does not require any additional actions or tuning in the public API — it is enabled by default.
Before the version 25.6 the archive documents were supported by the GroupDocs.Viewer in a specific way, without showing the tree hierarchy, only with a paged view, showing only one folder at a page. Performance was also not so good as it could be, especially on big archives.
Starting from the version 25.6, the completely new archive processing mechanism has completely replaced the old one. Now the list of contents of archives is rendered as archive entries are actually stored, in tree-like pageless view, where separation on pages are done only for paged formats like PDF, PNG, and JPEG, and now this page splitting is not dependent on specific folders. Performance was also drastically improved, especially while rendering archives to HTML.
Was this page helpful?
Any additional feedback you'd like to share with us?
Please tell us how we can improve this page.
Thank you for your feedback!
We value your opinion. Your feedback will help us improve our documentation.


{kind=link}